You can use the merge() function from the pandas library to merge three dataframes with the indicator option in Python. Here's an example code:
pandas 라이브러리의 merge() 함수를 사용하여 Python에서 표시기 옵션을 사용하여 세 개의 데이터 프레임을 병합할 수 있습니다. 다음은 예제 코드입니다:
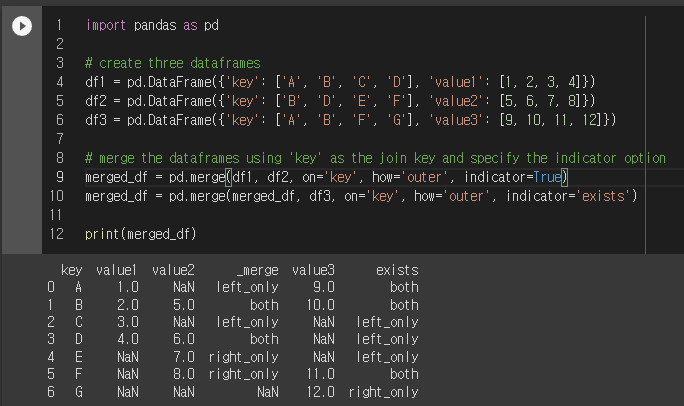
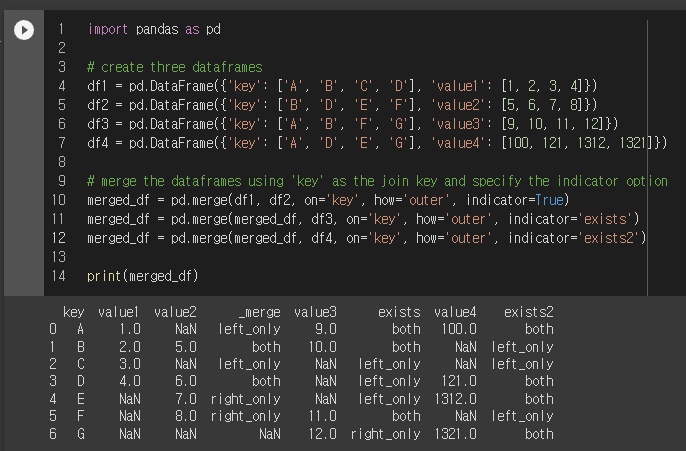
import pandas as pd
# create three dataframes
df1 = pd.DataFrame({'key': ['A', 'B', 'C', 'D'], 'value1': [1, 2, 3, 4]})
df2 = pd.DataFrame({'key': ['B', 'D', 'E', 'F'], 'value2': [5, 6, 7, 8]})
df3 = pd.DataFrame({'key': ['A', 'B', 'F', 'G'], 'value3': [9, 10, 11, 12]})
# merge the dataframes using 'key' as the join key and specify the indicator option
merged_df = pd.merge(df1, df2, on='key', how='outer', indicator=True)
merged_df = pd.merge(merged_df, df3, on='key', how='outer', indicator=True)
print(merged_df)
In this example, we create three dataframes df1, df2, and df3, each with a column named 'key'. We then use the merge() function to merge the dataframes, specifying 'key' as the join key and 'outer' as the merge method (which includes all keys from both dataframes). Finally, we set the indicator parameter to True to include a column indicating the source of each row in the merged dataframe. The result is stored in the merged_df variable and printed to the console.
이 예제에서는 각각 'key'라는 열이 있는 세 개의 데이터프레임 df1, df2, df3을 만듭니다. 그런 다음 merge() 함수를 사용하여 데이터 프레임을 병합하고, 조인 키로 'key'를 지정하고 병합 방법(두 데이터 프레임의 모든 키를 포함하는 병합 방법)으로 'outer'를 지정합니다. 마지막으로, 병합된 데이터 프레임에 각 행의 출처를 나타내는 열을 포함하도록 표시기 매개 변수를 True로 설정합니다. 결과는 merged_df 변수에 저장되고 콘솔에 인쇄됩니다.
위와 같이 답변을 받을 수 있었고, 이번에는 번역툴을 파파고나 아닌 딥엘이라는 번역기를 사용해서 작업을 해보았다.
(나쁘지는 않은듯~)
하지만!!!!
코드가 먹히지를 않는다!!!!
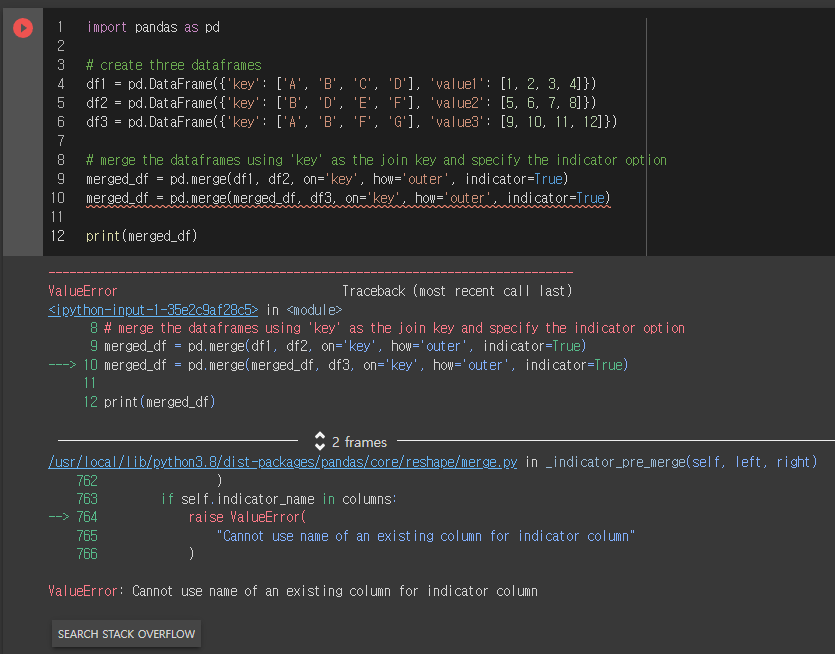
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
<ipython-input-1-35e2c9af28c5> in <module>
8 # merge the dataframes using 'key' as the join key and specify the indicator option
9 merged_df = pd.merge(df1, df2, on='key', how='outer', indicator=True)
---> 10 merged_df = pd.merge(merged_df, df3, on='key', how='outer', indicator=True)
11
12 print(merged_df)
2 frames
/usr/local/lib/python3.8/dist-packages/pandas/core/reshape/merge.py in _indicator_pre_merge(self, left, right)
762 )
763 if self.indicator_name in columns:
--> 764 raise ValueError(
765 "Cannot use name of an existing column for indicator column"
766 )
ValueError: Cannot use name of an existing column for indicator column
패치#노트코딩, 주식, 자동매매, 백테스팅, 데이터분석 등 관심 블로그
비전공자이지만 금융 및 관련 프로그래밍에 관심을 두고 열심히 공부중입니다.
우리 모두 경제적 자유를 위해 성공해봅시다!!
※ 혹시, 블로그 내용중 문제되는 내용있으시면 알려주시면 삭제/수정 토록하겠습니다.
※ 모든 내용들은 투자 권유가 아니오니 참고만 하시고, 또한 출처는 모두 표기토록 노력하겠으나 혹시 문제가 되는 글이 있다면 댓글로 남겨주세요~^^