[패스트캠퍼스 수강 후기] 데이터전처리 100% 환급 챌린지 28회차 미션 Programming/Python2020. 11. 29. 13:51
[파이썬을 활용한 데이터 전처리 Level UP- 28 회차 미션 시작]
* 복습
- 마지막 미션!!!!
- 범주형 변수 문자에 대한 처리 방법
- 이상치 제거.. 그리고 스케일링
[05. Part 5) Ch 20. 편향된 모델은 쓸모 없어 - 클래스 불균형 문제 - 01. 문제 정의 및 탐색 방법]

* 문제 정의
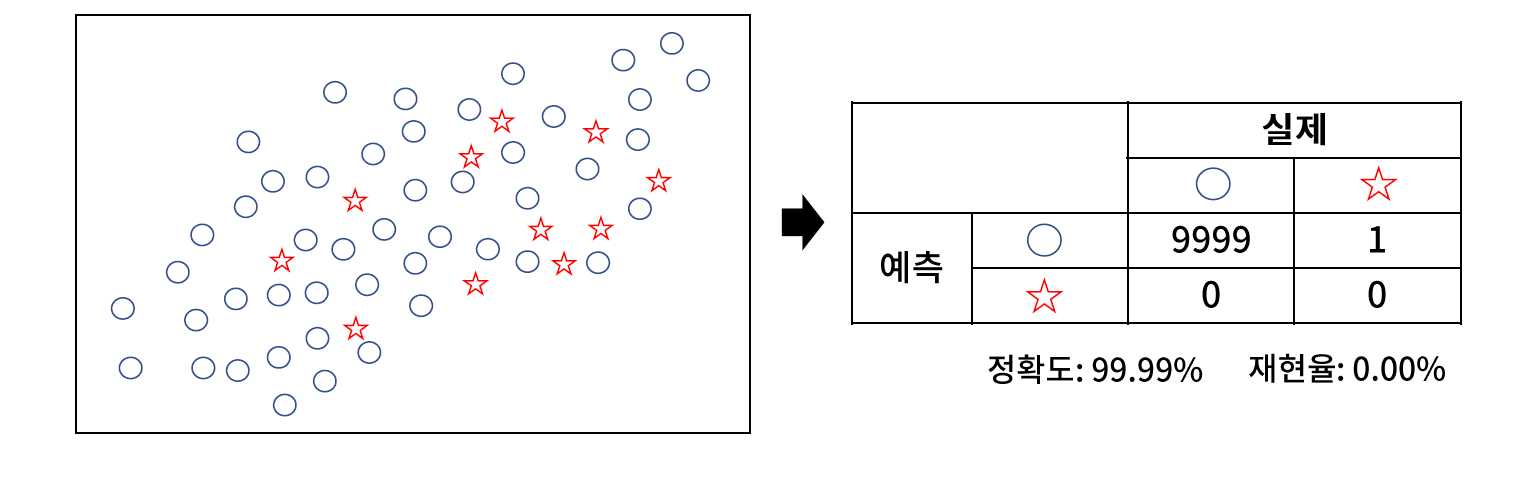
// 하나의 값에 치우친 데이터로 편향되는 문제
// 클래스 불균형 문제가 있는 모델은 정확도가 높고, 재현율이 매우 낮은 경향이 있다.
* 용어 정의
// 다수 클래스 : 대부분 샘플이 속한 클래스
// 소수 클래스 : 대부분 샘플이 속하지 않은 클래스
* 발생 원인

* 탐색 방법 (1) 클래스 불균형 비율

// 9 이상이면 편향된 모델이 학습될 가능성이 있다.
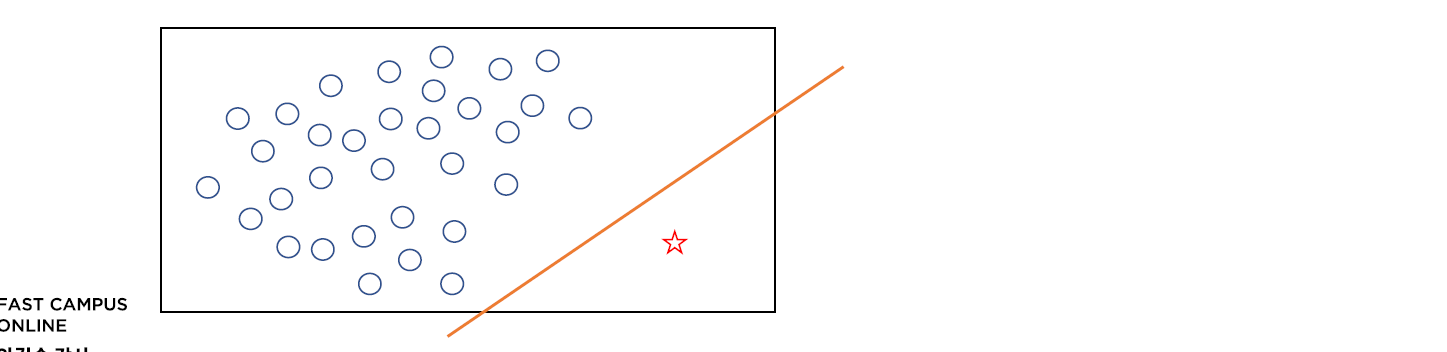
* 탐색 방법 (2) k- 최근접 이웃을 활용하는 방법
// k 값은 5~ 11 정도.. 보통은 11정도를 선호하는 수치이다.
* 문제 해결의 기본 아이디어

// 소수 클래스에 대한 결정 공간을 넓히는 것이다.
[05. Part 5) Ch 20. 편향된 모델은 쓸모 없어 - 클래스 불균형 문제 - 02-1. 재샘플링 - 오버샘플링과 언더 샘플링(이론)]

* 분류 : 오버샘플링과 언더샘플링

* 어디에 만들고 어느 것을 지울까?
// 결정 경계에 가까운 다수 클래스 샘플을 제거하고, 결정 경계에 가까운 소수 클래스 샘플을 생성해야 한다.

// 평가 데이터에 대해서는 절대로 재샘플링을 적용하면 안된다!!!!
* 대표적인 오버샘플링 알고리즘 : SMOTE

* imblearn.over_sampling.SMOTE Documentation
imbalanced-learn.org/stable/generated/imblearn.over_sampling.SMOTE.html
classimblearn.over_sampling.SMOTE(*, sampling_strategy='auto', random_state=None, k_neighbors=5, n_jobs=None)[source]
Class to perform over-sampling using SMOTE.
This object is an implementation of SMOTE - Synthetic Minority Over-sampling Technique as presented in [1].
Read more in the User Guide.
Parameters
sampling_strategyfloat, str, dict or callable, default=’auto’
Sampling information to resample the data set.
When float, it corresponds to the desired ratio of the number of samples in the minority class over the number of samples in the majority class after resampling. Therefore, the ratio is expressed as
where
is the number of samples in the minority class after resampling and
is the number of samples in the majority class.
Warning
float is only available for binary classification. An error is raised for multi-class classification.
When str, specify the class targeted by the resampling. The number of samples in the different classes will be equalized. Possible choices are:
'minority': resample only the minority class;
'not minority': resample all classes but the minority class;
'not majority': resample all classes but the majority class;
'all': resample all classes;
'auto': equivalent to 'not majority'.
When dict, the keys correspond to the targeted classes. The values correspond to the desired number of samples for each targeted class.
When callable, function taking y and returns a dict. The keys correspond to the targeted classes. The values correspond to the desired number of samples for each class.
random_stateint, RandomState instance, default=None
Control the randomization of the algorithm.
If int, random_state is the seed used by the random number generator;
If RandomState instance, random_state is the random number generator;
If None, the random number generator is the RandomState instance used by np.random.
k_neighborsint or object, default=5
If int, number of nearest neighbours to used to construct synthetic samples. If object, an estimator that inherits from sklearn.neighbors.base.KNeighborsMixin that will be used to find the k_neighbors.
n_jobsint, default=None
Number of CPU cores used during the cross-validation loop. None means 1 unless in a joblib.parallel_backend context. -1 means using all processors. See Glossary for more details.
* 대표적인 언더샘플링 알고리즘 : NearMiss
// 평균 거리가 짧은 다수 클래스 샘플을 순서대로 제거하는 방법이다.

// version 2 소수 클래스 샘플까지의 평균 거리를 사용한다.
* imblearn.under_sampling.NearMiss Documentation
imbalanced-learn.org/stable/generated/imblearn.under_sampling.NearMiss.html
classimblearn.under_sampling.NearMiss(*, sampling_strategy='auto', version=1, n_neighbors=3, n_neighbors_ver3=3, n_jobs=None)[source]
Class to perform under-sampling based on NearMiss methods.
Read more in the User Guide.
Parameters
sampling_strategyfloat, str, dict, callable, default=’auto’
Sampling information to sample the data set.
When float, it corresponds to the desired ratio of the number of samples in the minority class over the number of samples in the majority class after resampling. Therefore, the ratio is expressed as
where
is the number of samples in the minority class and
is the number of samples in the majority class after resampling.
Warning
float is only available for binary classification. An error is raised for multi-class classification.
When str, specify the class targeted by the resampling. The number of samples in the different classes will be equalized. Possible choices are:
'majority': resample only the majority class;
'not minority': resample all classes but the minority class;
'not majority': resample all classes but the majority class;
'all': resample all classes;
'auto': equivalent to 'not minority'.
When dict, the keys correspond to the targeted classes. The values correspond to the desired number of samples for each targeted class.
When callable, function taking y and returns a dict. The keys correspond to the targeted classes. The values correspond to the desired number of samples for each class.
versionint, default=1
Version of the NearMiss to use. Possible values are 1, 2 or 3.
n_neighborsint or object, default=3
If int, size of the neighbourhood to consider to compute the average distance to the minority point samples. If object, an estimator that inherits from sklearn.neighbors.base.KNeighborsMixin that will be used to find the k_neighbors.
n_neighbors_ver3int or object, default=3
If int, NearMiss-3 algorithm start by a phase of re-sampling. This parameter correspond to the number of neighbours selected create the subset in which the selection will be performed. If object, an estimator that inherits from sklearn.neighbors.base.KNeighborsMixin that will be used to find the k_neighbors.
n_jobsint, default=None
Number of CPU cores used during the cross-validation loop. None means 1 unless in a joblib.parallel_backend context. -1 means using all processors. See Glossary for more details.
[05. Part 5) Ch 20. 편향된 모델은 쓸모 없어 - 클래스 불균형 문제 - 02-2. 재샘플링 - 오버샘플링과 언더 샘플링(실습)]
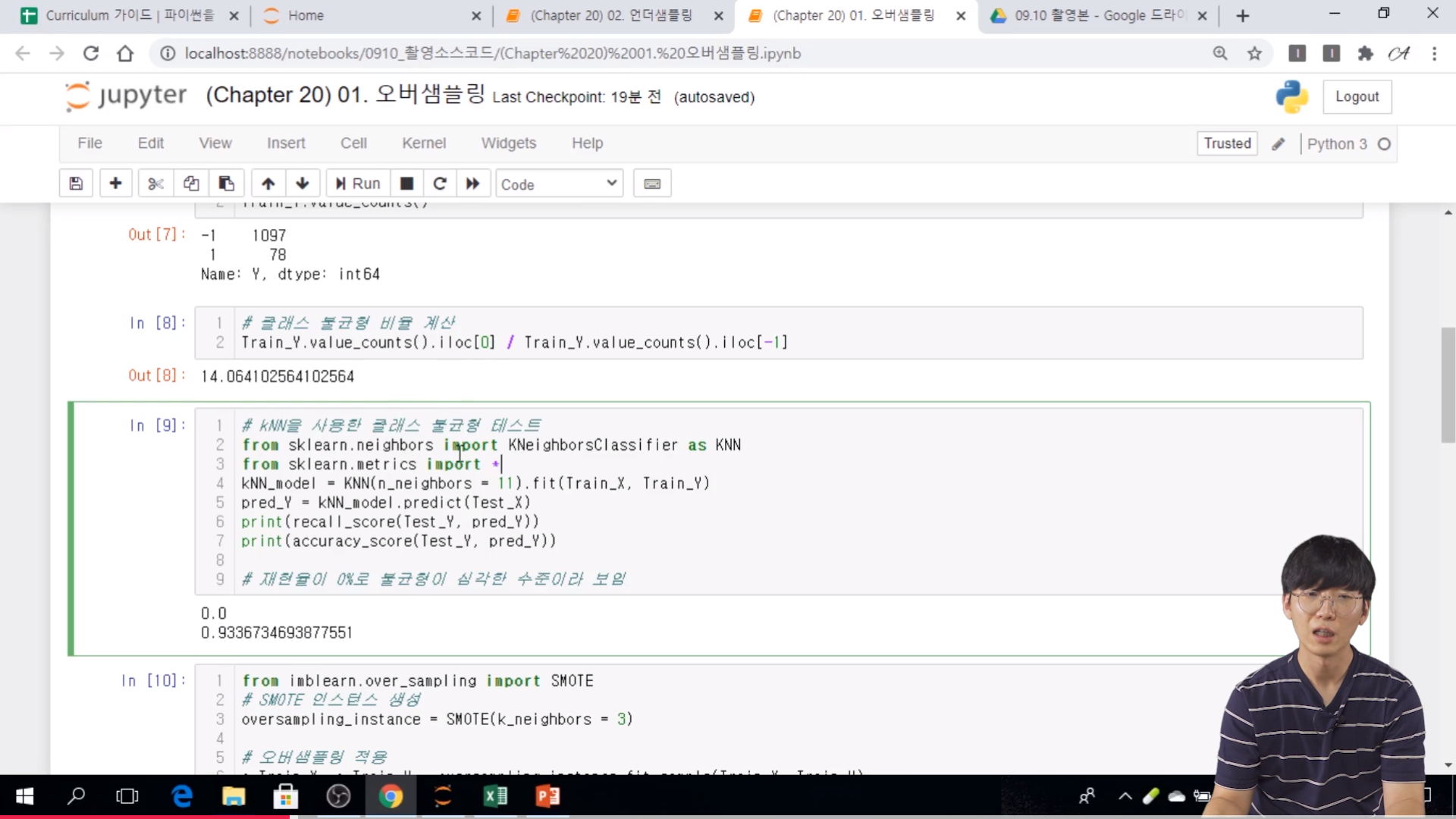
// kNN 을 사용해서 클래스 불균형도 테스트를 해준다.
// KNeighborsClassifier
// 재현율 0% 로 불균형이 심각한 수준이라 볼 수 있다.

[05. Part 5) Ch 20. 편향된 모델은 쓸모 없어 - 클래스 불균형 문제 - 03-1 비용 민감 모델 (이론)]

// 모델의 학습 변경한 모델이라고 볼 수 있다. 전처리라고 보기는 좀 어렵다.
* 정의
// 비용을 위양성 비용보다 크게 설정

* 확률 모델
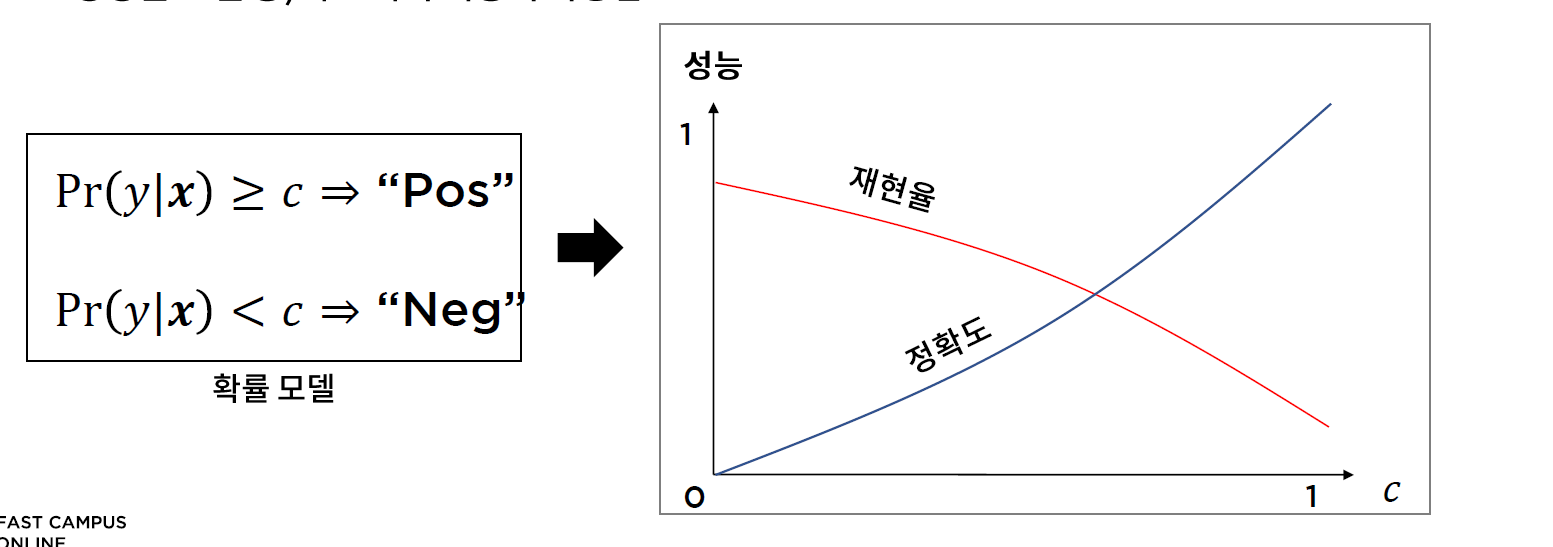
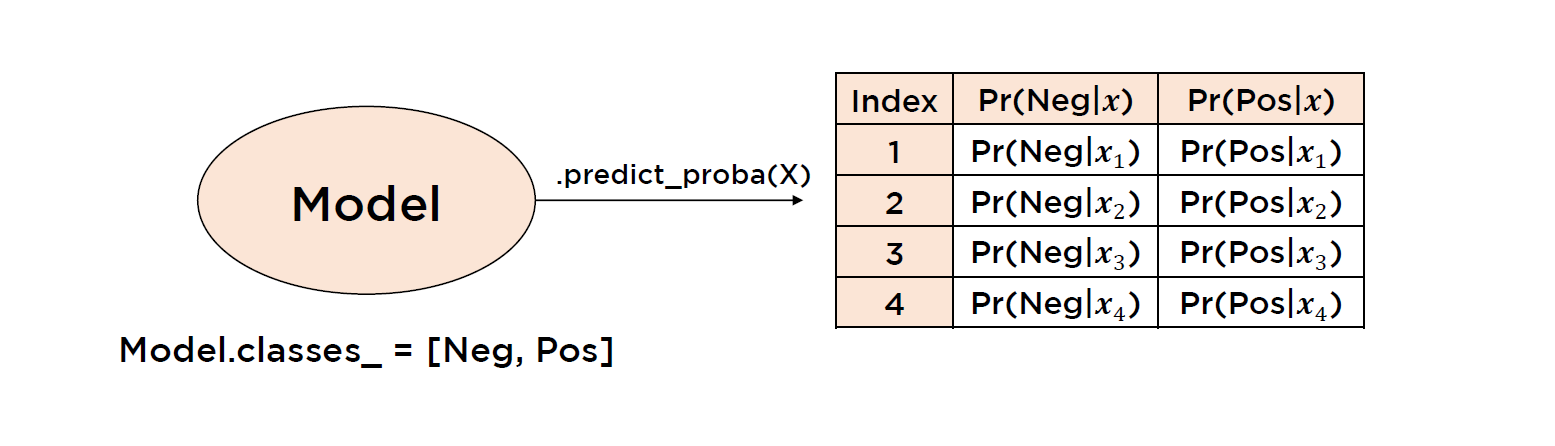
* 관련문법: .predict_proba
* Tip.Numpy 와 Pandas 잘 쓰는 기본 원칙 : 가능하면 배열 단위 연산을 하라
// 유니버설 함수, 브로드캐스팅, 마스크 연산을 최대한 활용

* 비확률 모델 (1) 서포트 벡터 머신

* 비확률 모델 (2) 의사결정 나무

* 관련문법 : class_weight
[05. Part 5) Ch 20. 편향된 모델은 쓸모 없어 - 클래스 불균형 문제 - 03-2 비용 민감 모델 (실습)]
* 실습
// kNN 을 사용한 클래스 불균형 테스트들을 사용

// cost_sensitive_model 의 함수를 만들어 준다.
// 둔감하다는 표현이 더 좋은 표현이라고 생각하면 된다.

// class weight 도 튜닝을 해야 한다고 보면 된다.
// sklearn.svm.SVC Documentation
scikit-learn.org/stable/modules/generated/sklearn.svm.SVC.html
class sklearn.svm.SVC(*, C=1.0, kernel='rbf', degree=3, gamma='scale', coef0=0.0, shrinking=True, probability=False, tol=0.001, cache_size=200, class_weight=None, verbose=False, max_iter=-1, decision_function_shape='ovr', break_ties=False, random_state=None)
C-Support Vector Classification.
The implementation is based on libsvm. The fit time scales at least quadratically with the number of samples and may be impractical beyond tens of thousands of samples. For large datasets consider using sklearn.svm.LinearSVC or sklearn.linear_model.SGDClassifier instead, possibly after a sklearn.kernel_approximation.Nystroem transformer.
The multiclass support is handled according to a one-vs-one scheme.
For details on the precise mathematical formulation of the provided kernel functions and how gamma, coef0 and degree affect each other, see the corresponding section in the narrative documentation: Kernel functions.
Read more in the User Guide.
Parameters
Cfloat, default=1.0
Regularization parameter. The strength of the regularization is inversely proportional to C. Must be strictly positive. The penalty is a squared l2 penalty.
kernel{‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘precomputed’}, default=’rbf’
Specifies the kernel type to be used in the algorithm. It must be one of ‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘precomputed’ or a callable. If none is given, ‘rbf’ will be used. If a callable is given it is used to pre-compute the kernel matrix from data matrices; that matrix should be an array of shape (n_samples, n_samples).
degreeint, default=3
Degree of the polynomial kernel function (‘poly’). Ignored by all other kernels.
gamma{‘scale’, ‘auto’} or float, default=’scale’
Kernel coefficient for ‘rbf’, ‘poly’ and ‘sigmoid’.
if gamma='scale' (default) is passed then it uses 1 / (n_features * X.var()) as value of gamma,
if ‘auto’, uses 1 / n_features.
Changed in version 0.22: The default value of gamma changed from ‘auto’ to ‘scale’.
coef0float, default=0.0
Independent term in kernel function. It is only significant in ‘poly’ and ‘sigmoid’.
shrinkingbool, default=True
Whether to use the shrinking heuristic. See the User Guide.
probabilitybool, default=False
Whether to enable probability estimates. This must be enabled prior to calling fit, will slow down that method as it internally uses 5-fold cross-validation, and predict_proba may be inconsistent with predict. Read more in the User Guide.
tolfloat, default=1e-3
Tolerance for stopping criterion.
cache_sizefloat, default=200
Specify the size of the kernel cache (in MB).
class_weightdict or ‘balanced’, default=None
Set the parameter C of class i to class_weight[i]*C for SVC. If not given, all classes are supposed to have weight one. The “balanced” mode uses the values of y to automatically adjust weights inversely proportional to class frequencies in the input data as n_samples / (n_classes * np.bincount(y))
verbosebool, default=False
Enable verbose output. Note that this setting takes advantage of a per-process runtime setting in libsvm that, if enabled, may not work properly in a multithreaded context.
max_iterint, default=-1
Hard limit on iterations within solver, or -1 for no limit.
decision_function_shape{‘ovo’, ‘ovr’}, default=’ovr’
Whether to return a one-vs-rest (‘ovr’) decision function of shape (n_samples, n_classes) as all other classifiers, or the original one-vs-one (‘ovo’) decision function of libsvm which has shape (n_samples, n_classes * (n_classes - 1) / 2). However, one-vs-one (‘ovo’) is always used as multi-class strategy. The parameter is ignored for binary classification.
Changed in version 0.19: decision_function_shape is ‘ovr’ by default.
New in version 0.17: decision_function_shape=’ovr’ is recommended.
Changed in version 0.17: Deprecated decision_function_shape=’ovo’ and None.
break_tiesbool, default=False
If true, decision_function_shape='ovr', and number of classes > 2, predict will break ties according to the confidence values of decision_function; otherwise the first class among the tied classes is returned. Please note that breaking ties comes at a relatively high computational cost compared to a simple predict.
New in version 0.22.
random_stateint or RandomState instance, default=None
Controls the pseudo random number generation for shuffling the data for probability estimates. Ignored when probability is False. Pass an int for reproducible output across multiple function calls. See Glossary.
Attributes
support_ndarray of shape (n_SV,)
Indices of support vectors.
support_vectors_ndarray of shape (n_SV, n_features)
Support vectors.
n_support_ndarray of shape (n_class,), dtype=int32
Number of support vectors for each class.
dual_coef_ndarray of shape (n_class-1, n_SV)
Dual coefficients of the support vector in the decision function (see Mathematical formulation), multiplied by their targets. For multiclass, coefficient for all 1-vs-1 classifiers. The layout of the coefficients in the multiclass case is somewhat non-trivial. See the multi-class section of the User Guide for details.
coef_ndarray of shape (n_class * (n_class-1) / 2, n_features)
Weights assigned to the features (coefficients in the primal problem). This is only available in the case of a linear kernel.
coef_ is a readonly property derived from dual_coef_ and support_vectors_.
intercept_ndarray of shape (n_class * (n_class-1) / 2,)
Constants in decision function.
fit_status_int
0 if correctly fitted, 1 otherwise (will raise warning)
classes_ndarray of shape (n_classes,)
The classes labels.
probA_ndarray of shape (n_class * (n_class-1) / 2)probB_ndarray of shape (n_class * (n_class-1) / 2)
If probability=True, it corresponds to the parameters learned in Platt scaling to produce probability estimates from decision values. If probability=False, it’s an empty array. Platt scaling uses the logistic function 1 / (1 + exp(decision_value * probA_ + probB_)) where probA_ and probB_ are learned from the dataset [2]. For more information on the multiclass case and training procedure see section 8 of [1].
class_weight_ndarray of shape (n_class,)
Multipliers of parameter C for each class. Computed based on the class_weight parameter.
shape_fit_tuple of int of shape (n_dimensions_of_X,)
Array dimensions of training vector X.
Methods
Evaluates the decision function for the samples in X. | |
fit(X, y[, sample_weight]) | Fit the SVM model according to the given training data. |
get_params([deep]) | Get parameters for this estimator. |
predict(X) | Perform classification on samples in X. |
score(X, y[, sample_weight]) | Return the mean accuracy on the given test data and labels. |
set_params(**params) | Set the parameters of this estimator. |
[파이썬을 활용한 데이터 전처리 Level UP-Comment]
- 각 불균형 문제에 대해서 샘플링 및 비용 민감 모델을 어떻게 다룰 것인지에 대해서 학습했다.
파이썬을 활용한 데이터 전처리 Level UP 올인원 패키지 Online. | 패스트캠퍼스
데이터 분석에 필요한 기초 전처리부터, 데이터의 품질 및 머신러닝 성능 향상을 위한 고급 스킬까지 완전 정복하는 데이터 전처리 트레이닝 온라인 강의입니다.
www.fastcampus.co.kr
'Programming > Python' 카테고리의 다른 글
| KRX 회원사별 어디갔니? (0) | 2021.01.19 |
|---|---|
| 패스트캠퍼스 파이썬을 활용한 데이터 전처리 Level UP 챌린지 참여 후기 (0) | 2020.12.08 |
| [패스트캠퍼스 수강 후기] 데이터전처리 100% 환급 챌린지 27회차 미션 (0) | 2020.11.28 |
| [패스트캠퍼스 수강 후기] 데이터전처리 100% 환급 챌린지 26회차 미션 (0) | 2020.11.27 |
| [패스트캠퍼스 수강 후기] 데이터전처리 100% 환급 챌린지 25회차 미션 (0) | 2020.11.26 |


